

From Meaning to a Noise: Inside the Forward Process of Diffusion Models (DDMs)
A Closer Look into the Noise Process of DDMs.


Table of Content
Introduction.
Notations.
Problem Definition.
The Unreparameterized Forward Process.
Reparametrization Trick.
The Reparameterized Forward Process
Merging Two Gaussian Distributions.
The Equation.
Diffusion Schedule
Linear Schedule.
Cosine Schedule.
Offset-Cosine Schedule.
Recap.
References.
1. Introduction
In the last post, we briefly discussed denoising diffusion models (DDMs). We learned that the diffusion model is a type of generative model that tries to learn the distribution of data by modeling the data generation using a denoising process. Also, we knew the main components of the diffusion models, and how the forward process and reverse process help us to generate a novel sample from a completely random noise.
Today, we will address the forward process component in detail. We will learn how the diffusion models will transform a meaningful input into a random noise through a sequential process to learn a data distribution and generate novel samples. First, we will explain the forward process by defining the problem. Then, we will talk about an important trick that is used in Bayesian statistics to handle stochastic processes.
After that, we will derive the main equation of the forward process. Finally, we will talk about an important technique that helps in optimizing the performance of the diffusion models and minimizing the reverse process objective function, the diffusion schedule. Let’s dive in!
2. Notations
3. Problem Definition
3.1 In Words
The process of adding a small amount of noise to a sample gradually over many steps until the sample is converted to completely standard Gaussian noise.
3.2 In Math
Let’s assume that we have a data point x that is sampled from a distribution d and we want to perturb it by adding a noise ε sampled from a Gaussian distribution N(0, I) over T steps. The variances of the noisy samples over the T steps:
are provided by a scheduler S :
For example S = [0.001, 0.03, 0.34 ] for T =3.
4. The Unreparameterized Forward Process
Given that we have a function q that adds a small amount of Gaussian noise to a data point x over T steps, we can define the mathematical form of q as follows (Eq1):
where:
Also, we should note that q is a Gaussian distribution. So if we want to express the joint probability of all the values of x over T steps, we can express it as the product of conditional probabilities:
5. Reparametrization Trick
The previous equation of the forward process can be written in a much simpler way. Suppose that we want to calculate the noisy sample of x at a step t = 25 but without calculating all the values from t = 1 to t = 25. In other words, we want to be able to calculate that in just one operation (Jumping directly to t = 25).
The parameterization trick can help us to do that. But before jumping to see the simpler version of the forward process equation, let’s explain briefly what the reparameterization trick is.
The parameterization trick is a technique used in Bayesian statistics to express a stochastic random variable z as a deterministic variable.
Mathematically, the stochastic form of z is:
The parameterization trick will help us to express it in a deterministic form:
Why do we want to do that?
Suppose that we want to optimize the q function with respect to its parameters(i.e. Φ). We can’t do this optimization, and find the best values of the parameters that produced the best output for that q function.
This is because of the sampling process nature. It is a stochastic operation that can’t be differentiated. Each time we call the function q above, it will give us a different value due to the randomness of the sampling operation itself. This makes calculating the gradient of this function undefined.
Therefore, to be able to calculate the gradients, the parameterization trick helps us to change the stochastic operation to a deterministic operation by decoupling the stochasticity from the main equation as follows:
where:
As we can see, now the epsilon is sampled from a standard Gaussian distribution, and then added to the equation as a constant. This simple trick helps the gradient of a loss function f to be calculated with respect to the parameters (i.e. Φ). Here is a visual illustration of that:

6. The Reparameterized Forward Process
6.1 Merging Two Gaussians Distributions
In statistics, we learned that if we have two Gaussian distributions:
If we want to merge or combine them G = G1 + G2, we can do the following:
The new mean will be:
And the new variance will be:
w1 and w2 are parameters that control how much contribution we want from each distribution.
In the case of standard Gaussian distributions, where the mean is zero and the variance is 1 or the identity vector, the mean and variance of the merged distributions will be:
6.2 The Reparameterized Forward Process
Let’s jump back to see how the reparameterization trick helps us to get a close form of the previous forward process equation. Here, the trick is used to get a close form, and not to mainly simplify the gradient flow as we saw in the previous section.
The previous equation (Eq1):
is expressed using the parameterization trick using a deterministic equation as follows (Eq 3):
Now, given the deterministic equation, let’s derive the close form of the forward process by defining some important variables:
Alpha
Alpha Product
The product of alpha(s) in all the steps from i = 0 to i = t can be expressed as:
Now, let’s calculate the value of x at step = t-1 (Eq 4)
Let’s substitute that in (Eq3) as follows:
Now, let’s use the merging property of the two Gaussians where:
Given that, they are standard Gaussian distributions:
Now, (Eq3) will be transformed as follows:
Where:
Now, if we keep the substitution, we could notice the pattern of Alpha Product:
Then, if we keep the expansion till t = 0, then (Eq3) will be as follows:
And this is the close form of the forward process (Eq4):
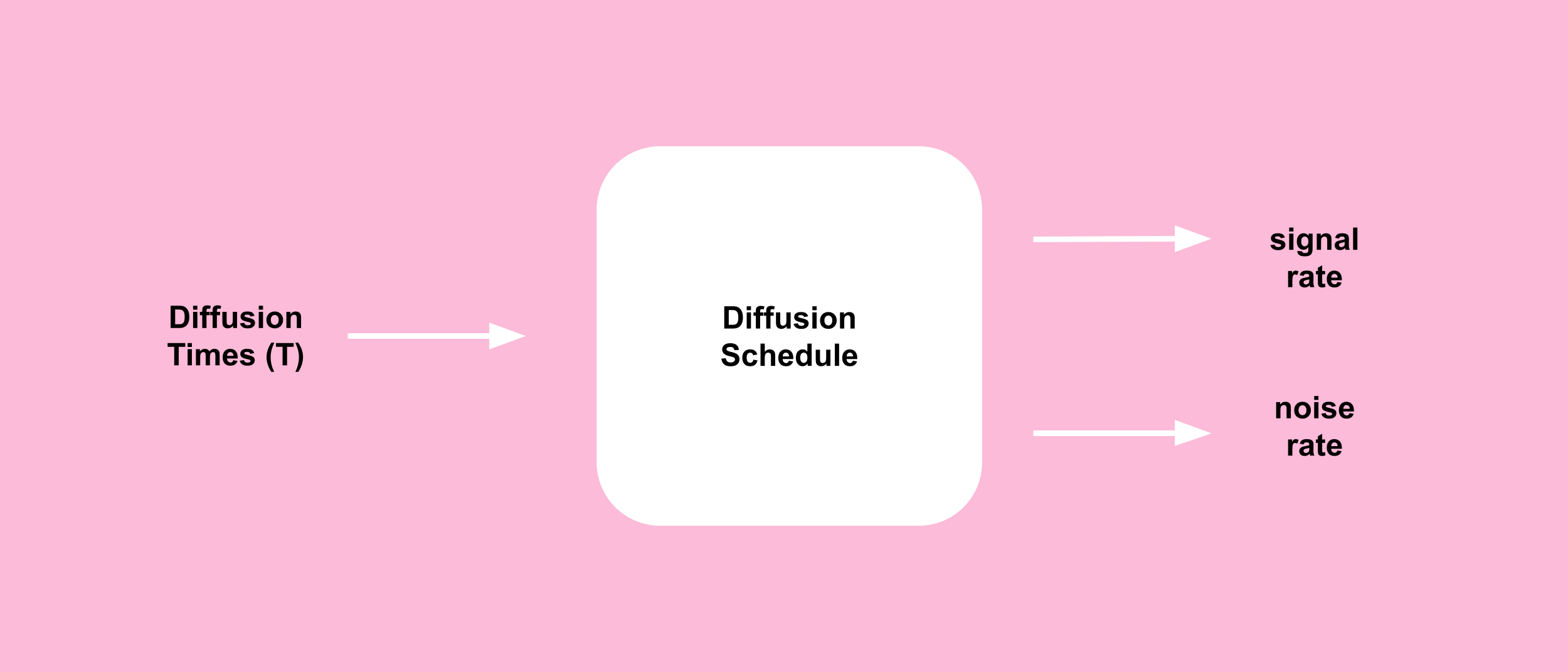
7. Diffusion Schedule
A diffusion schedule is a technique that describes how the values of beta change with t.
At the early stage of the nosing process, we use smaller values of beta then we start to increase it with time.
There are multiple ways to apply the scheduling during the diffusion process, here are some of the popular methods:
Linear Diffusion Schedule: In this type of schedule the values of beta over all the time steps T are generated linearly, where the range of these values usually falls in the range [0.0001 - 0.02]. This means, the noising process will have a linear form during the diffusion operation:
\(\beta_t \in [10^{-4}, 0.02]\)Cosine Diffusion Schedule: Cosine scheduling achieved a better performance compared to linear scheduling [Nichol & Dhariwal]. Here is the formula used to update x during the T timesteps:
\(\begin{array} {lcl} \bar \alpha_t &= &\frac{f(t)}{f(0)} \\ f(t) &=& cos(\frac{t }{T} . \frac{\pi}{2})^2 \end{array}\)Offset-Coine Diffusion Schedule: This is similar to the cosine diffusion schedule, except we will add a small number of s to the equation to prevent beta from being too small at t = 0.
\(\begin{array} {lcl} \bar \alpha_t &= &\frac{f(t)}{f(0)} \\ f(t) &=& cos(\frac{t/T + s}{1+s} . \frac{\pi}{2})^2 \end{array}\)
Note
You could notice that in the image above the diffusion schedule component outputs two values: 1) The signal rate, and 2) The noise rate, as we need these values in the forward proces equation (Eq4).We defined these values in the “Notations” section above, but here is another reminder for you:
\(\begin{array}{lcl} \\ \bar \alpha_t &\equiv& \text{The signal rate at arbitrary step t.} \\ 1-\bar \alpha_t &\equiv& \text{The noise variance rate at arbitrary step t.} \end{array}\)
The next figure shows the difference in performance between linear scheduling and cosine scheduling during the training process:

Your Takeaway From This Post

The Forward Process Equation For Denoising Diffusion Models (DDMs) is:
8. Recap
In this post, we talked about the forward process in denoising diffusion models (DDMs). This is how we turn meaningful data into random noise.
We started by defining the forward process and showing how to express it in math.
We also introduced a useful trick from Bayesian statistics that helps us to obtain the closed form of the forward process.
Then, we showed you the main equation that describes how the forward process works mathematically.
Finally, we talked about the diffusion schedule, which describes how the values of beta change with t.
See You Soon!
9. References
Jonathan Ho, Ajay Jain, and Pieter Abbeel. "Denoising Diffusion Probabilistic Models" (2020).
Alex Nichol and Prafulla Dhariwal. "Improved Denoising Diffusion Probabilistic Models" (2021).
David Foster's "Generative Deep Learning, 2nd Edition" (2023).
Lilian Weng. "What are Diffusion Models?" (2021). Lilian Weng's Blog
Lilian Weng. "Reparameterization Trick - From Autoencoder to Beta-VAE" (2018).
Want to Cite this Article?
@article{khamies2023meaning,
title = "From Meaning to a Noise: Inside the Forward Process of Diffusion Models (DDMs)",
author = "Waleed Khamies",
journal = "Zitoon.ai",
year = "2023",
month = "Aug",
url = "https://publication.zitoon.ai/from-meaning-to-a-noise-inside-the-forward-process-of-diffusion-models"
}New to this Series?
New to the “Generative Modeling Series”? Here you can find the previous articles in this series [link to the full series].
Any oversights in this post?
Please report them through this Feedback Form, we really appreciate that!

Thank you for your reading!
Thank you for your reading! If you would like to receive the next posts in this series in your email, please feel free to subscribe to the ZitoonAI Newsletter. Come and Join the Family!